《狂野大数据》是传智教育旗下博学谷品牌推出的,针对有IT行业经验人员的大数据技术体系在职提升课
课程包含完整的大数据体系中常用的组件和技术,内容丰富有深度。场景式教学、真·实战项目以及贴合企业实际需求的内容编排,确保教学质量和学员的吸收效果。同时固定周期直播+视频回看的授课方式,满足了学习时间的灵活性。指定城市月薪不达15K或18K全额退还学费的保障,让您的学习无后顾之忧。
学完收获 :
熟练使用DS、Oozie、AirFlow等任务调度工具,完成大数据任务调度
熟悉Linux基本操作,完成分布式虚拟机搭建任务
了解数据仓库开发从需求沟通、标签定义、编码开发、整个流程
能够利用Python语言完成Spark编程任务
能够利用Java完成MapReduce编程,Flink任务编程
熟练掌握Hadoop生态体系
掌握MapReduce原理及优化技巧
熟悉掌握Spark生态技术栈
能够利用SparkCore完成基础数据处理
能够使用SparkSQL完成大数据数据处理及统计分析
能够利用HiveSQL完成基础数据仓库构建
能够利用Spark On Hive完成企业级离线数据处理及统计工作
熟练Mysql数据库
能够完成Spark/Hadoop/HBase/Kafka/Flink等组件的搭建
能够基于Flink进行实时分析和离线分析
掌握Flink核心4大基石
能够基于FlinkSQL完成常见大数据统计分析任务
能够使用Hbase完成大数据异构数据存储
能够掌握Kafka消息队列基础使用
能够掌握Kafka和Flume对接完成实时数据采集工作
熟练使用FineBi等BI工具完成数据展示任务


学完后具备如下能力: 1. 能够熟练使用Linux系统;2. 能够使用Linux命令来管理操作磁盘、权限、网络等;3. 能够通过基于SHELL脚本编写程序;4. 能够通过脚本控制程序自动化执行;5. 掌握分布式服务协调系统原理并应用;6. 掌握大数据常用操作系统管理、运维能力。
学完后具备如下能力: 1,掌握集群的环境准备、搭建能力;2,掌握HDFS的使用;3,掌握基于HDFS编程;4,理解MapReduce原理和应用场景;5,掌握Yarn的原理和组件。
学完后具备如下能力: 1,掌握Hive的使用;2,掌握Hive的架构;3,掌握OLAP的设计特点;4,能够运用HQL开发ETL;5,能够使用各种策略进行Hive调优。
学完后具备如下能力: 1,掌握从需求、设计、研发、测试到落地上线的完整项目流程。2,掌握大数据量场景下优化配置。3,掌握拉链表的具体应用,新增、更新数据的抽取和分析。4,掌握hive函数的具体应用等。5,掌握基于CM的大数据环境部署和管理。6,掌握数据仓库的核心概念和应用。7,掌握最常用的离线大数据技术:oozie、Sqoop、hive等。8,掌握FineBI可视化。
学完后具备如下能力: 1,掌握Python语言基础数据结构; 2,掌握Python语言高阶语法特性; 3,掌握Spark的RDD、DAG、CheckPoint等设计思想; 4,掌握SparkSQL结构化数据处理,Spark On Hive整合; 5,掌握SparkStreaming偏移量管理及Checkpoint; 6,掌握Structured Streaming整合多数据源完成实时数据处理。
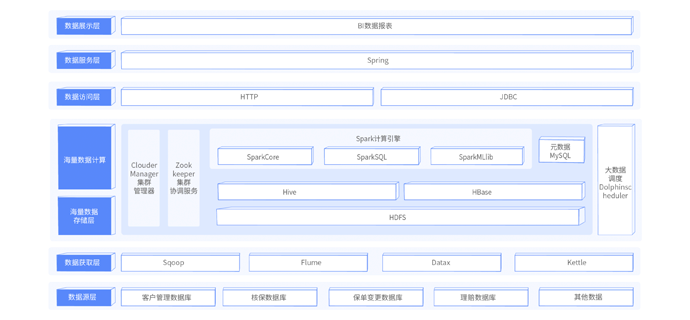
学完后具备如下能力: 1.掌握快速搭建保险行业大数据平台能力; 2.掌握SparkSQL轻松应对复杂的迭代计算; 3.掌握基于Spark分析12亿报单表和8千万客户等数据; 4.掌握保单汇总各类业务指标计算; 5.熟悉基于SpringCloud搭建Web平台。
学完后具备如下能力: 1,掌握Redis原理及架构; 2,掌握Hbase原理及架构; 3,掌握使用HBase存储清洗、转换后的海量数据; 4,掌握使用HBase结合Phoneix进行优化查询; 5,掌握Kafka原理及架构。
学完后具备如下能力: 1.掌握基于Flink进行海量数据集的实时和离线数据处理、分析; 2.掌握基于Flink的多流并行处理技术; 3.掌握Flink中的事件时间窗口计算。
学完后具备如下能力: 1.掌握基于Flink全栈进行快速OLAP分析; 2.掌握实时高性能海量数据分析与存储; 3.掌握针对HBase调优实现HBase存储优化; 4.掌握数据报表分析; 5.掌握业务数据实时大屏场景实现; 6.项目上线部署、运维监控。
学完后具备如下能力:

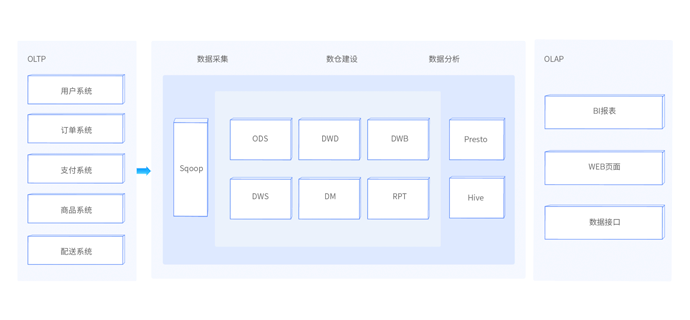
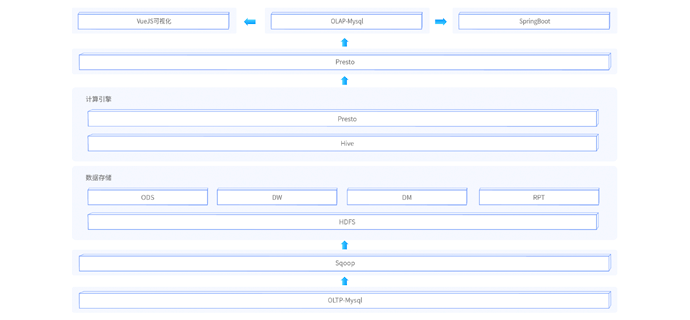
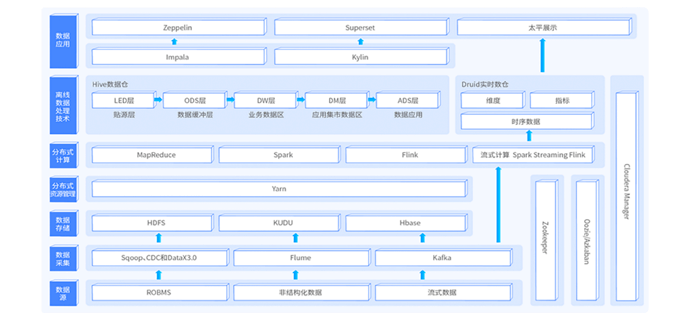
本阶段为大数据的核心项目实战课程,该阶段课程将之前所学习的所有阶段课程集成在一起,将技术真正地应用在实际的业务场景中。该项目课程为新零售行业的真实大数据项目转换而来,项目中大量使用到目前离线数仓的主流技术。例如:采用ClouderaManager快速搭建大数据平台,采用sqoop进行数据导入导出、采用Hive作为离线数仓引擎、采用Oozie作为离线作业调度、使用FineBI工具作为可视化BI工具等。项目经过精心设计,从项目的需求、技术架构、业务架构、部署平台、ETL设计、作业调度等整套完整pipeline。
技术亮点:
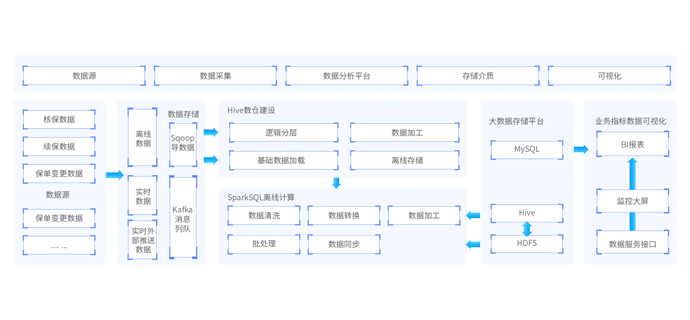
课程涵盖真实保险行业相关业务和实时业务,从项目核心架构和业务流程、Hive数仓建模 、Sqoop数据同步开发 DolphinScheduler任务调度、使用lag,sum等窗口函数 、使用UDAF函数计算有效保单数字段、计算现金价值、计算和准备金、分区表的使用 、指标汇总计算 、Shuffle优化。以企业主流的Spark生态圈为核心技术(Spark、Spark SQL、Structured Streaming)、Spring Cloud数据微服务开发、存储和计算性能调优、还原企业搭建大数据平台的完整过程。
技术亮点:
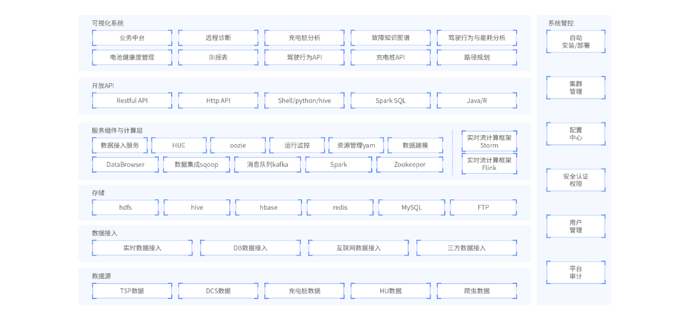
近年来,国家大力推广新能源汽车产业,汽车附加产业。随着车辆设备终端技术的发展,收集车辆数据高度精确且极其高效。大型车企累计大量数据,在传统模式数据存储和计算方式下,无法满足原始车辆数据高效存储、快速计算、智能推荐等需求,此系统应运而生。车联网大数据系统通过TBOX车辆终端收集车辆上报原始数据,通过嵌入式代码解析为TSP数据、DCS数据、充电数据、HU数据,原始数据经过ETL转换存储到数仓中,存储到NoSQL数据库系统中与分布式文件系统上。在计算与服务层,提供实时计算服务与离线计算服务,最终通过API接口提供数据查看,以报表和大屏展示分析结果数据。
技术亮点:
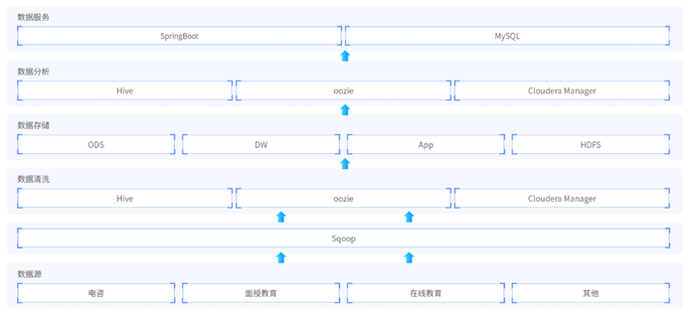
还原大型在线教育的大数据平台,建立企业数据仓库,统一企业数据中心,把分散的业务数据集中存储和处理。项目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序,项目中挖掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
技术亮点:


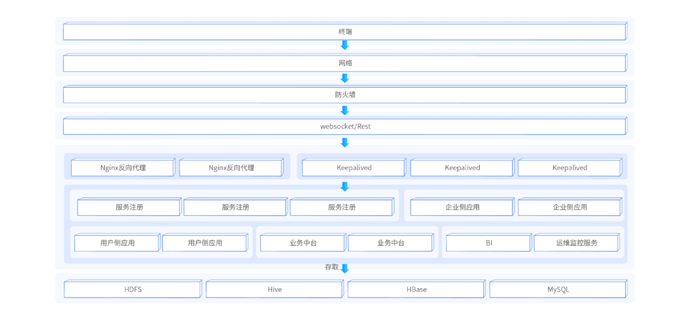
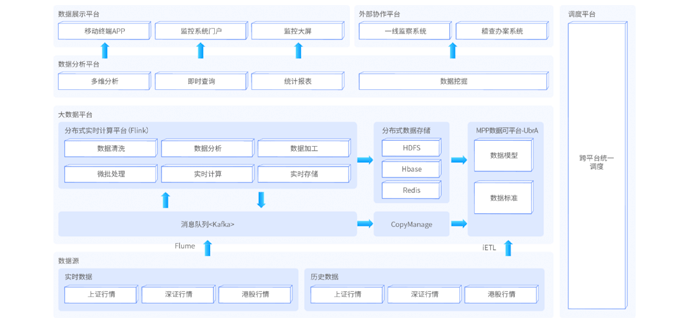
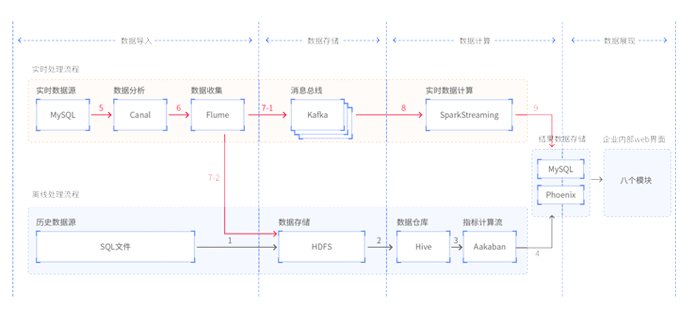
本阶段为大数据体系中实时数据处理方向的项目实战阶段。近些年来,众多企业开始进行数字化转型,越来越多的业务直接依赖于大数据技术的支撑。企业对大数据技术的时效性要求也越来越高,很多企业都开始启动实时大数据项目,以大量的高性能、低延迟、高容错的实时组件来完善实时大数据项目的架构。该项目中覆盖了大型实时项目的完整流程。从海量实时数据的采集、到实时数据的计算、到落地存储、到监控预警、到实时展示等。并且能够从项目中学习到大量的技术解决方案实现,帮助学生完成更高层级的就业。
技术亮点:
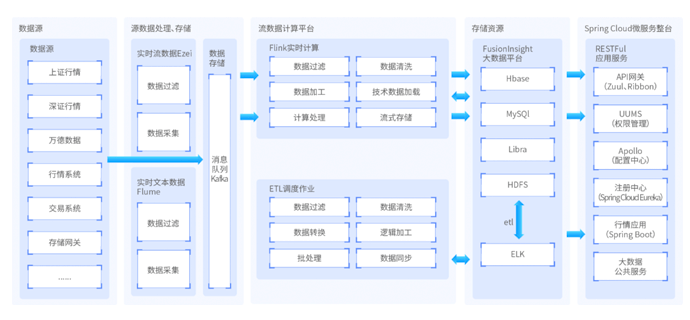
本项目是基于大型物流公司业务研发的智慧物流大数据平台,公司业务网点覆盖国内各地,大规模的客户群体,日订单达1000W,平台对千亿级数据进行整合、分析、处理,保障业务的顺利进行。
技术亮点:
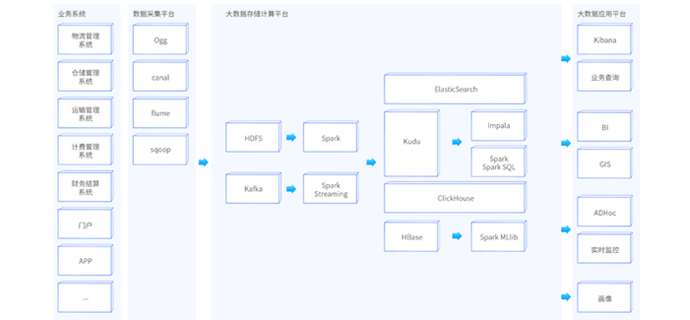
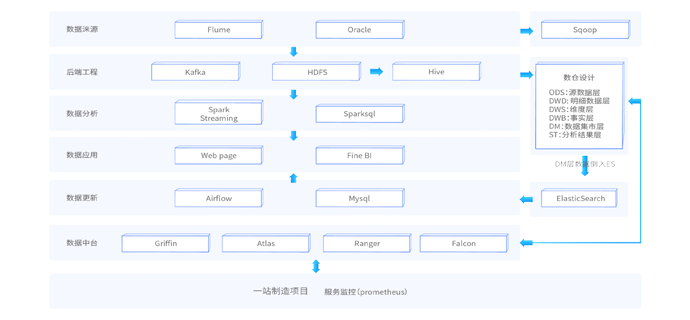
通过大数据技术架构,解决工业物联网石油制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于hive数仓分层来存储各个业务指标数据,基于sparksql做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
技术亮点:
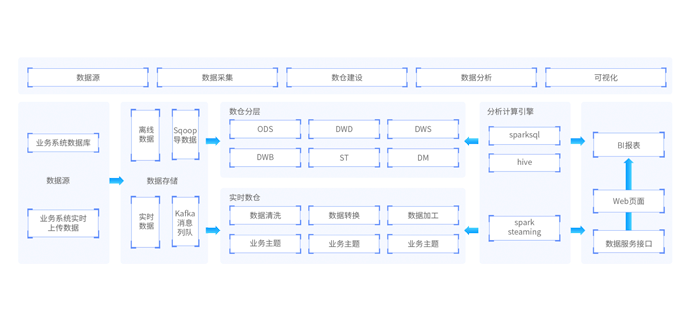
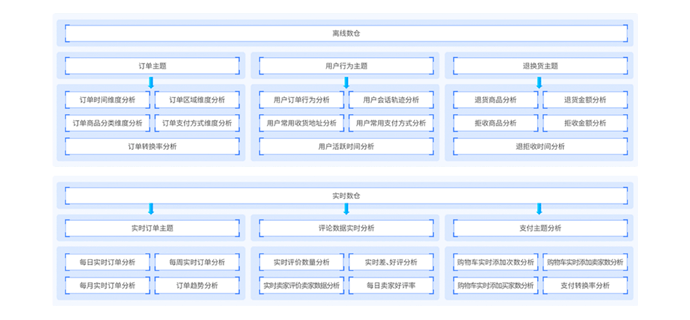
智数电商主要是对来自全品类B2B2C电商系统的数据进行分析,数据仓库分为离线数仓和实时数仓,技术框架依托于大数据CDH发型版构建。智数电商在业务上贴近企业实际需求,指标计算完成后采用开源BI工具Apache superset对指标数据进行可视化展示。
技术亮点:
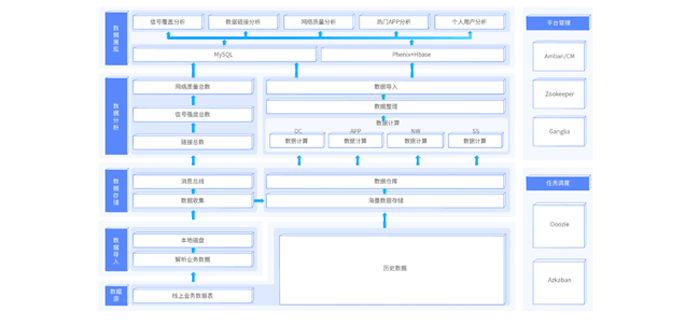
已经是人们生活中重要的通信、咨询、娱乐工具,本项目基于手机测速软件采集的数据,对用户的网速、上行下行流量、网络制式、信号强度等信息进行宏观分析,根据数据分析结果,计算出附近通讯厂商包括移动、联通、电信的信号强度。
技术亮点:
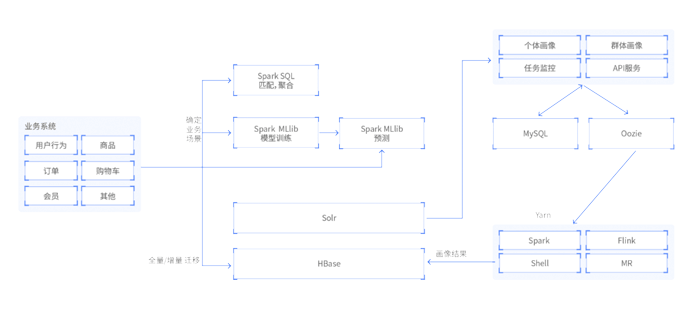
以某知名电商用户画像系统为基础二次开发,形成本项目。包含了几乎所有的常见标签类型的计算思路,也具有数个机器学习类型的标签,标签种类充足。采用 Spark 进行数据开发,使用 Spring 系统作为业务系统开发,包含了从部署到标签计算的全流程。
技术亮点:
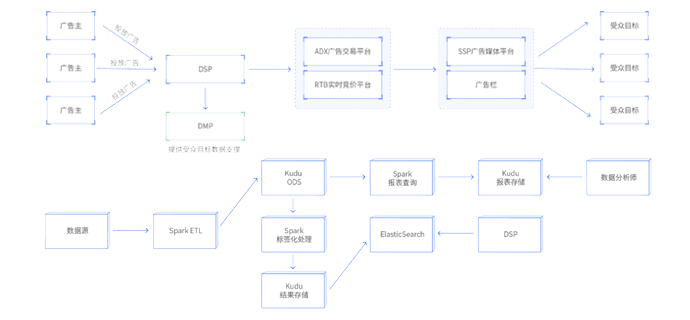
DMP全称数据管理系统,为广告系统提供数据服务,其中涉及标签处理、用户识别、图计算等技术点,可以帮助学员强化大数据开发能力。
技术亮点:
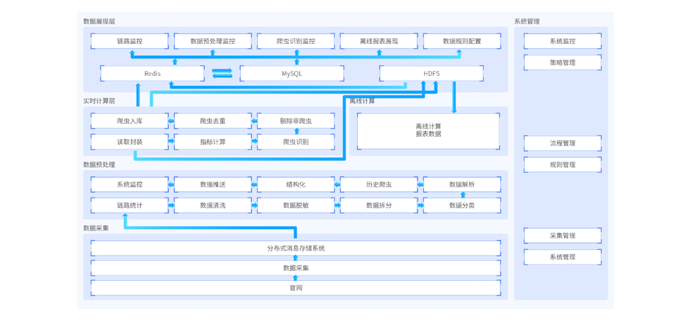
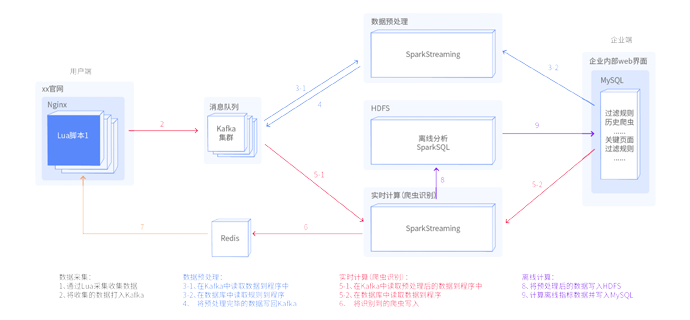
天知票务反爬系统,是一款大数据防爬工具,该项目采用Lua+Spark+Redis+Hadoop框架搭建,包含状态监控、反爬指标配置、运营指标监控展示等主要功能,能够限制爬虫访问,从而解决各大订票网站恶意占座、系统资源虚耗、系统波动等问题。
技术亮点: